



 Branimir Valentic
Branimir Valentic By providing IT services, a service provider creates value that a customer receives. To avoid a gap between (customer) expectations and reality (of how services are provided), the value created should be measured. There are several ways, i.e. parameters, of how this can be done. Availability of the service is just one of them.
It’s simple – we agree with the customer as to a certain service level, which includes targeted availability, and then we measure (availability) achievement. Easy to say, but how does it work in practice?
In real wor(l)ds
It is important to say – availability of services significantly shapes customer satisfaction (or dissatisfaction). I assume that I don’t have to explain the negative effects of unavailable service. Therefore, both service providers and customers need plain numbers that will provide information about service availability. In addition to service availability, some components (or Configuration Items – CIs) that form the service will be measured, and their availability parameters analyzed and reported. All this implies that availability must be managed.
Availability management is about monitoring, measuring, analyzing and reporting of the following aspects:
- Availability –the ability of the service or component to provide the agreed-upon functionality when required. You will find it expressed in percentage (%), e.g. service has availability of 99.95 %. It is calculated as follows:
- Reliability – expressed in hours (e.g. 2.600 h), it measures how long a service or component can fulfill its function without interruption. You will find two parameters that measure reliability:
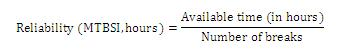
- Maintainability – measures how quickly a service or component can be restored to normal operation after a failure (e.g. 10 h). It is calculated as follows:
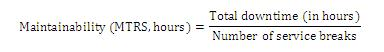
- Serviceability – the ability of a third party to fulfill obligations expressed in agreed levels of availability, reliability and maintainability. Using these measurements, you can assure that your suppliers are performing as agreed.
My experience is that Service Level Agreements (SLAs) usually define only availability requirements, and rarely reliability and maintainability.
Integration with Incident Management
So, service incidents happen. Is that the end? It shouldn’t be. One of the principles of Availability management is that customer satisfaction can still be achieved, even if incidents occur. How? By assisting Incident Management to ensure that incidents are resolved as quickly as possible and that the impact of incidents is minimized.
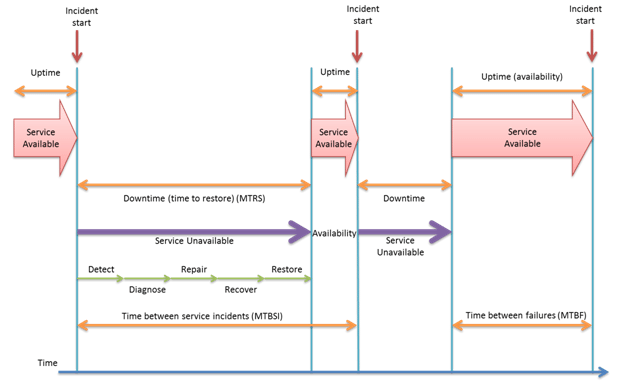 Figure: Incident lifecycle
Figure: Incident lifecycle
The above figure shows incident lifecycle, as seen from an availability point of view. Each stage can be measured to provide valuable information in incident management analysis. Based on this data, weak points, i.e. possibilities for improvement, can be pointed out. Here are more details about particular stages of the lifecycle, as well as few examples of how partial measurements during downtime detect weak points:
- Incident detection – Service provider is aware of an incident. Measurement can point out that monitoring, i.e. event tools performance, is not appropriate.
- Incident diagnosis – In this phase, diagnosis is completed to detect the cause of an incident. Time elapsed in this phase will depend on quality of diagnosis tools, scripts…etc.
- Incident repair – The failure has been fixed. This measurement will test escalation procedures inside the organization or from external parties.
- Incident recovery – Component recovery has been completed. Efficiency of this phase depends on recovery and test plans and procedures.
- Incident restoration – Service is resumed. These measurements provide information about efficiency of the procedures, which verify that service has been restored.
When such measurements are analyzed, they could result in detection of lost time, e.g. incident restore took 2 hours, but applying a resolution took only 15 minutes. Analysis of other measurements, like detection and diagnosis time, will answer the question.
I have seen some examples of availability reports that concluded in event monitoring tool replacement (an event is one of the triggers of incidents) due to the fact that the detection phase took too long.
Importance of Availability management
In case this has not been stated clearly enough, availability management supports and forms an integral part of many other processes in ITIL. That increases the importance of measurements on which availability management relies heavily. It is true that “if you don’t measure it – you can’t improve it,” but more interestingly, “if you don’t measure it – you probably don’t care,” which is dangerous from a revenue point of view.
Download a free sample of our Availability Management process template to learn more about the process.




