

 Neven Zitek
Neven Zitek While ITIL Problem Management has a logical and easy-to-understand description, implementing Problem Management within your own organization is extremely challenging. It happens more often than not, that Problem Management doesn’t produce any of the desired outputs upon implementation. In order to prevent that, you must recognize the importance of both the reactive and proactive parts of ITIL Problem Management.
At this point, I’d recommend reading ITIL Problem Management: getting rid of problems just to establish a general overview of the relationship between Incident Management and Problem Management.
Reactive Problem Management
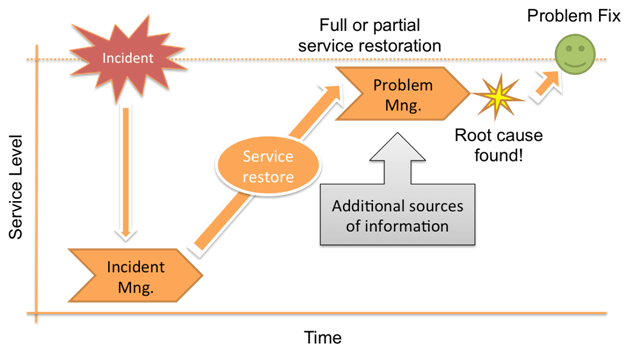
Figure 1: Reactive Problem Management
Reactive Problem Management reacts to incidents that have already occurred, and focuses effort on eliminating their root cause and reoccurrence. The main focus of Problem Management is to increase long-term service stability and, consequently, customer satisfaction.
When incidents start to occur, IT organizations want Problem Management involved early, but Incident Management strives to resolve the incident and restore service to usable levels as quickly as possible, and during that process, some important indications about root cause may be lost. So, in order to effectively pinpoint root cause, Problem Management may block Incident Management efforts to restore service. This is where confusion may arise regarding the difference between Incident Management and Problem Management.
What we need is clear and well-defined hand-over procedure, with agreed time frames within which Incident Management stops, and Problem Management starts. There should also be an agreed set of information that Incident Management passes to Problem Management during the hand-over, which includes what has been done so far, whether any workarounds are in place, information about affected Configuration Items (CIs), or other important information.
Problem Management processes all that information and outputs Requests for Change, updates the Known Error Database (KEDB) and Work-Arounds, updates Problem Records and produces management information.
Proactive Problem Management
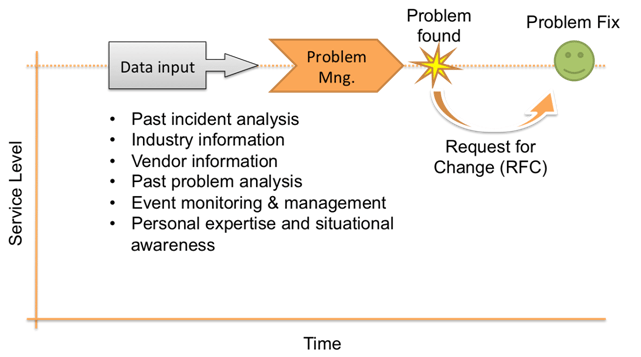
Figure 2: Proactive Problem Management
Even though Reactive Problem Management relies heavily on other Service Management components, Proactive Problem Management relies even more. Proactive Problem Management is a continuous process that doesn’t wait for an incident (or series of incidents) to happen in order to react; it’s always active and always on guard.
Proactive Problem Management is extremely challenging in an environment where you have lots of services, different technologies, and many things going on at the same time. So, what makes efficient Proactive Problem Management?
With Proactive Problem Management, the focus is on continuous data analysis, and in order to do that, you need a large volume of quality data. There are several data analysis techniques that Proactive Problem Management uses in daily operation:
- Pain Value Analysis – Instead of analyzing the number of incidents related to a specific CI or system over time, Pain Value Analysis is focused on the “level of pain” those incidents brought to the business. The formula for calculating “pain level” is: Pain value = (No. of incidents) x (duration) x (1/severity) x (weighting factor). It’s very useful for detecting problems with equipment that is invisible to end-users (network routers, VOIP gateways, etc.).
- Pareto Analysis – This is another great method for finding root cause for most common trivial issues. Group the incident/problem data by common group type, and create a cumulative percentage table. Drawing a graph will reveal the common group type that generates 80% of all incidents/problems, and you can focus further investigation from there.
- Kepner-Tregoe® method – Kepner-Tregoe is a Registered Trademark of Kepner-Tregoe, Inc. in the United States and other countries, and is mentioned within ITIL materials related to Problem Management as one of the data analysis techniques. It revolves around: defining the problem, describing the problem in terms of identity, location, time (duration) and size (impact), establishing possible causes, testing the most probable cause, and verifying the true cause.
So, what’s so confusing about ITIL Problem Management?
You may be aware that ITIL Service Management practice components deeply rely on and interact with each other. Some may be observed in more “independent” fashion, but some can’t exist even on the drawing board without other components being implemented first.
One of the greatest examples of heavily dependent component is ITIL Problem Management. It’s closely related to Incident Management, and Incident Management is one of the first ITIL components that IT organizations implement. With basic Incident Management in place, organizations believe that Problem Management is simply an add-on, which can be used to “upgrade” Incident Management with Problem Management.
But, Problem Management can hardly be of any use if there is no Change Management, Asset Management, Configuration Management, Event Management, Availability Management, Capacity Management, Knowledge Management and many more components in place. Problem Management heavily relies on data stored throughout the Service Lifecycle in order to be effective.
I can give you a good example of Problem Management reliance on other Service Management components: A customer had repeatedly reported issues with his laptop performance, and the Incident Management team repeatedly resolved it by simply reinstalling the computer, over and over again. The customer was obviously not thrilled with the solution, but each incident was resolved within the SLA, and on the surface, everything looked peachy. However, repeated occurrence of the incident on the same asset triggered the Problem Management process, and after brief analysis, the results were very surprising. The customer initially had a SSD drive installed, but a year ago ordered a new one with larger capacity. At roughly the same time, the first incident reports about slow performance started. After deeper analysis, Problem Management discovered that the new hard drive installed was, in fact, not a SSD, and moreover, it was the large capacity variant of the slowest model possible. Even deeper analysis revealed that the customer, when ordering the new drive, never stated that it should be SSD, and the vendor delivered a regular, slow, high-capacity type.
Without quality data from the Incident, Asset, Change, and Configuration Management – Problem Management would be useless in this situation.
To implement ISO 20000 easily and efficiently, use our ISO 20000 Documentation Toolkit that provides step-by-step guidance for full ISO 20000 compliance.



