

 Drago Topalovic
Drago Topalovic Various authors have discussed Incident Management here on several occasions. Being one of the most elaborated key functions, there are a number of issues we could address in depth. Major incident management is one of them, and due to its significant impact and visibility, it deserves a few more words.
ITIL Incident Management Overview
Any unplanned interruption or service degradation is, according to ITIL, considered as incident. So once incident happens, and they will, primary goal of ITIL Incident Management is to restore service as quickly as possible in order to minimize the business impact. Any event that disrupts or could disrupt a service itself is within the scope of incident management. For an example, single failed disk drive within mirrored array is not causing any interruptions, but there is a service degradation in terms that risk of data loss has increased, and that’s why such event is also considered as an incident.
ITIL Incident Management, as part of ITIL Service Management, is responsible for incident identification, logging and categorization. Reports about incidents may come from Service Desk (by call, e-mail, web), event management or directly by technical staff, but all of them have to be recorded, time stamped and contain sufficient data in order to be properly managed.
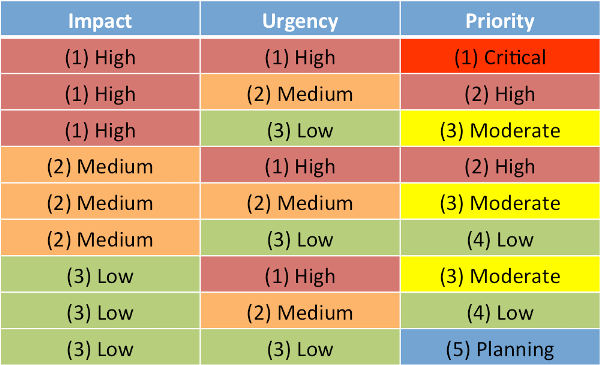
In order to effectively manage incidents, we need to have means to prioritize them, because they rarely appear only one at the time. And we prioritize incidents by Impact vs. Urgency matrix. Impact is the effect incident has on a business, and Urgency basically defines time business (or customer) is ready to wait for resolution. In example, we may have high impact incident (high level – 1) affecting whole finance department, but low urgency (low level – 3) because they use that service only on the end of the fiscal year which is 6 months away. In such scenario, this incident is categorized as moderate priority – 3. Details about time frames in which each level of priority is expected to be resolved is part of Service Level Agreement (SLA). Read this blog post for more information: All About Incident Classification.
Incidents are generally results of errors or malfunctions within IT equipment. In such cases, root cause is apparent, and resolution is simple as repairing faulty part, or applying a workaround. But in a case where seriousness of the incident is great, or avalanche of similar incidents are recorded, Problem Management process steps in and takes over the search for the root cause. Once root cause has been identified, problem is referred as known error, and is registered in Known Error Database (KeDB). Service Desk, as a function of the Incident Management relies on known error database and workarounds provided. If you need a tool that will help you manage incidents, here is the list of Free tools for ITSM that you may try, and use for free.
What is a major incident?
In theory, a major incident is a highest-impact, highest-urgency incident. It affects a large number of users, depriving the business of one or more crucial services. Business and IT have to agree on what constitutes a major incident. It is one of the rare occasions where ITIL is strict in terms of definition: it MUST be agreed on. ISO 20000 requirements on major incident management are short, but demanding: agreement, separate procedure, responsibility and review.
In practice, you know a major incident when you see it: a large number of Service Desk calls, customer impatience, rage of the management, panic. All the more reason to get it straight before it happens. In most cases, it will simply be the highest-priority incident in the impact/urgency matrix. You might have a look at my Incident Classification article. In some cases, IT and the business can decide that only special types of high-priority incidents will be marked as major incidents. This can be due to different SLA parameters with various businesses. For example, when you support a chain of pharmacies or tobacco shops, they will want their cash register service malfunction to be marked as priority one, with strict resolution times defined. If you support another organization, say finance or marketing departments in the same corporation, their SLA will tend to address different issues, different response and resolution times, and probably a different amount of resources for the resolution.
Who should be involved?
When a major incident occurs, roles and the process should be strictly defined. Mind you, we are talking about the roles here, not the actual day-to-day jobs. Roles will differ according to the size of the IT service management organization and the scope of its service management. Smaller organizations will tend to aggregate a few roles into one job definition, while larger organizations will elaborate sub-roles for each major incident type, customer or technical expertise field.
Major incident manager. Accountable for the general procedure management, taking care that the required resources for incident resolution are engaged and the customer is informed appropriately about the progress. He shall also have basic technical knowledge about the outage. In smaller service management organizations with a lower frequency of major incidents, this role will be taken by the Service Desk manager, who also acts as the Incident Manager. In larger organizations, the appointment of major incident manager will depend on the particular expertise area. It could be the technical account manager best acquainted with the respective business organization specifics, someone from the Technical management function or the Application management function.
Problem manager. This role will often have to be involved, since major incident resolution usually requires finding the underlying cause (root cause analysis) of the major incident. This role can’t be combined with the incident management role, due to the well-known conflict of interests between the incident management and problem management processes. The major incident team will be struggling to restore the service, and problem management tends to take its time finding the root cause.
Change manager. Involved in case some urgent changes have to be implemented to restore the service.
SLA manager. Must be informed in order to keep a record of the downtime and to inform the customer if the procedure requires this.
Service Desk. Responsible for keeping incident records up to date and for primary customer communication.
Communication
We mentioned major roles in the process. Guess whose is the most important role, and who is often omitted from the loop? The customer! It is the most common mistake for growing service management organizations – to get involved so deeply in incident resolution that the communication with the customer is neglected.
The moment you receive the call from the customer to inquire about the resolution progress, you should know that there is something wrong. Frequency, form and the scope of communication with the customer should be clearly stated in the SLA. The customer should always know what to expect. His vital business process is endangered; he must be on his heels. Short, concise information every half an hour or at least every hour should contain info about:
- Start of downtime
- Short description of the known cause of the downtime
- The impact of the downtime
- Estimated time for restoration
- Next scheduled information
The major incident team should maximize its resources in service restoration, so the Service Desk should regularly ping them to receive a quick update about the process, which they will forward formally to the customer.
The after party
The incident is resolved, the service is restored, and the customer returns to his day-to-day business. The aftertaste remains. Why did it happen? What is to be expected going forward – have we done anything to prevent these downtimes in the future? How do we deal with these questions?
In short, the best practice is to resolve the incident and to continue working on a related problem ticket. This will produce a so-called problem report, or at least a root cause analysis (RCA) report in a brief, SLA-defined period of time to the customer. Recommended info in this report should consist of at least the following:
- Short description of the incident
- Downtime duration
- SLA impact
- Short incident history
- How we resolved the incident
- What is the root cause
- A set of activities scheduled in order to prevent this kind of downtime

This report will soothe the customer’s concerns, and let him know that he is dealing with mature service management which understands his business needs, and is doing its best to protect his core business.
If you were the customer, what more would you expect?
To implement ISO 20000 easily and efficiently, use our ISO 20000 Documentation Toolkit that provides step-by-step guidance and all documents for full ISO 20000 compliance.



