

 Neven Zitek
Neven Zitek The most known quote in the world: “Houston, we have a problem,” was spoken by Apollo 13’s Commander Jim Lovell. (Actually, he said, “Houston, we’ve had a problem,” but that’s not what we will discuss today.) This quote is one of the best examples of the distinction between ITIL terminology and everyday language. According to ITIL, what Commander Lovell wanted to report was not the problem; it was an incident. An incident is any event that causes degradation or disruption of a service, or even the potential disruption of a service. On the other hand, a problem is the root cause of the incident(s). So, when the Apollo 13 crew heard a loud bang and saw voltage and oxygen pressure drop, they experienced a series of incidents, all stemming from the same root cause – one of the oxygen tanks exploded. However, at the time, that information was unknown – therefore, the problem was unknown.
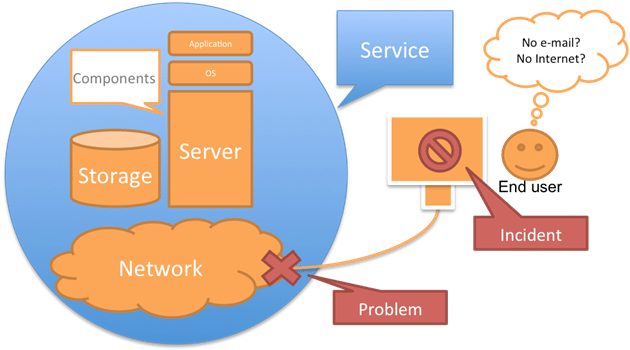 Figure 1: Clear distinction between Incident and Problem according to ITIL terminology; this time the example is not within the space flight realm, but rather IT related.
Figure 1: Clear distinction between Incident and Problem according to ITIL terminology; this time the example is not within the space flight realm, but rather IT related.
Once a problem is identified, the focus must be shifted to quick service restoration. If the service can’t be restored by normal means, such as replacement of a faulty component, any option that will restore service is acceptable, and that operation is called a Workaround. In such case, the problem (or incident) is referred to as a Known Error. So, let me go back once again to the Apollo 13 example, and explain in ITIL terms what was going on after the first Incident.
When workarounds become a way of delivering services – your daily dose of drama
After an analysis of available data and observation by the ground crew and astronauts, the problem was identified as the explosion and loss of one of the oxygen tanks. As oxygen is used for life support, engine fuel, and electric power generation, it was obvious that the command module (where the astronauts were) was no long providing the service it was designed for. The crew was instructed to abandon the command module and move into the lunar module (the part that was supposed to land on the Moon), and use its oxygen, navigation and propulsion. That decision is, in ITIL terms, called a workaround, as it restored service (the crew was able to breathe, communicate, and navigate the spacecraft) that was previously provided by the now-faulty command module. From that point on, the missing oxygen tank was, by ITIL terminology, referred to as a known error, as it was impossible for the crew to repair or replace it.
We could go even further in exploring ITIL Service Management terminology within the Apollo 13 flight; for example, when the crew was moved to the lunar module, after some time carbon dioxide (CO2) levels began to rise, due to the fact that three astronauts were breathing in a lunar module designed for two, and CO2 filters weren’t able to remove it quickly enough from the atmosphere. Normally, would be enough to replace the filters more often (which would be called a Standard Change, as it’s a common and well-known operation), but they had used all of the filters already, and had none left for the time required to get back to Earth. NASA summoned all available personnel on the ground, and tasked them with figuring out how to fit cube-shaped filters, used in the command module, into a cylindrical socket, available in the lunar module. The result of this action was an Emergency Change (which was not exactly tested, and was loosely documented on the go), that included yet another workaround using duct tape, parts of a manual, plastic bags, and one astronaut’s sock (hopefully the clean one) – and it worked.
Predicting events is easier if you monitor them
Within that single flight, we could describe a good portion of the ITIL best practices terminology that is in use today. As another example, astronauts were communicating with the ground crew via a single ground crew representative (CAPCOM – Capsule Communicator), which is very similar to the Service Desk role in an IT Service Management organization. On the other hand, the astronauts didn’t have a single communication representative, which is again similar to the Customer role in service management terms. The ground crew was continuously monitoring and interpreting all Events and logs coming from the spacecraft’s onboard systems, which is nothing more than Event Management and service monitoring. Therefore, when CO2 levels started to rise, that event was recorded, and even though it wasn’t at a critical level yet, it was reported as an incident, which consequently became a problem that got escalated to an emergency change, and was solved by a workaround. This chain of events is a display of good Service Management practice, as it enabled involved personnel to see, interpret, and react to events in way that led to a solution in time, in logical order, and it was resolved without service impact.
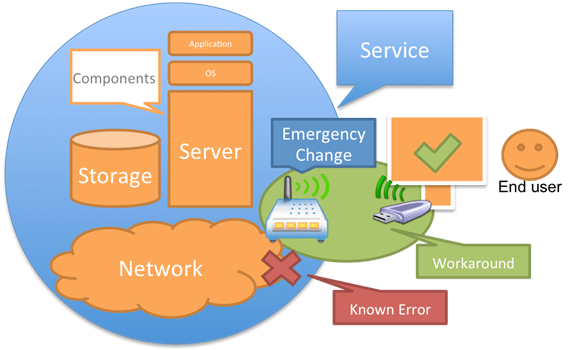 Figure 2: Service restoration by applying Workaround via Emergency Change, and resolving all related Incidents. Problem is now referred to as Known Error.
Figure 2: Service restoration by applying Workaround via Emergency Change, and resolving all related Incidents. Problem is now referred to as Known Error.
In general, what we deal with in IT organizations is not a matter of life and death, so the common approach to everyday tasks is much more casual than the one described in this space program example. However, what differentiates good Service Management from bad, is how well Service Management understands its role, its ability to predict, prevent and operate in any conditions. Clear communication with well-defined terminology that is based on good practice is just one of the success factors, whether we talk about day-to-day business, or mission-critical situations. If all personnel involved within the IT organization are able to understand, and use given terminology, they will consequently be able to share information better, avoiding common assumptions which lead to more issues, confusion and the good old blame game.
To implement ISO 20000 easily and efficiently, use our ISO 20000 Documentation Toolkit that provides step-by-step guidance for full ISO 20000 compliance.



