

 Neven Zitek
Neven Zitek For those of you who just tuned in, note that there is a part one of this article: ITIL Release and Deployment Management Part I – General principles and service testing, so I suggest that you read part one first, if you haven’t already. And, before we continue, allow me to briefly remind you of Part 1; we’ve discussed general principles of the ITIL Release and Deployment Management process and issues with “instant service deployment” practices, and described a variety of tests that should be performed before service deployment.
Once we’ve defined the Release and Deployment policies and performed various tests, such as Deployment Readiness, Service Operation tests, Service Level tests, Provider Interface tests and User tests, we can continue with choosing an appropriate deployment method.
Deployment methods
When designing a service, it’s important to properly select an adequate deployment method. The example I mentioned in the introduction would fall into the “big-bang” release category, which means releasing a service and all of it components at once to all end users. This “big-bang” option is used in areas where overall consistency is very important. An example would be any form of business management / supporting software.
A phased approach, on the other hand, is used when service is deployed to only group of end users, and release operation is repeated according to schedule. An example would be migration to a new e-mail server version or system, where end users are migrated sequentially when a need for the legacy system no longer exists, or when the capacity of the new system is enough to host a new group of end users.
New services can also be deployed using the push method, where the service (or component) is deployed centrally according to schedule, and end users can’t choose the time or postpone the deployment. The pull method is the opposite, where a service (or mostly software) is available in a central location and end users freely decide when to use it. Deployment may also be performed manually or by using some form of automation.
Early life support
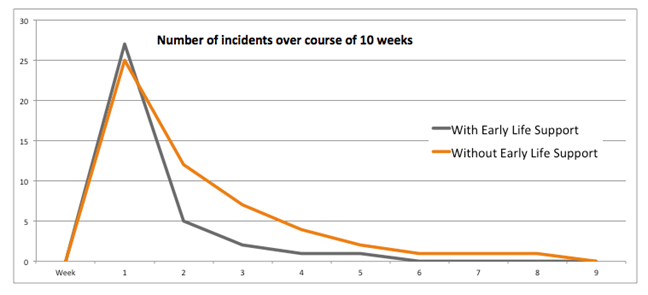 Figure 1 – Number of recorded incidents over time, on sites with and without early life support established.
Figure 1 – Number of recorded incidents over time, on sites with and without early life support established.
It’s considered really good practice to enable early life support immediately after service deployment, especially for new services, or major changes within the service itself. The main purpose of early life support is to quickly resolve any issues or defects that may appear in the live environment, and weren’t detected during testing.
As displayed in Figure 1 – you can see the comparison of incident numbers and resolution times between two locations similar in size, where on Site A support was performed by the service development team (which was coincidently located on Site A), and on Site B support was performed by the operations team.
Early life support is also very important for end users’ perception of the service provider, as people tend to be understanding of issues, but only if they are resolved quickly and in a satisfactory manner. It’s obvious that the service build/deployment team will be able to resolve any issues much faster that the operations support team, so early life support should not be left to operational support alone.
Common good practice for early life support is the so-called pilot phase, where the release is performed using a close group of end users who understand the change in more detail, and are willing to give constructive and informed feedback from a user point of view. In exchange, these users will receive direct support from the development team, and will get to use the service before anyone else does.
By using the pilot phase before a massive release, feedback from pilot users can be used to update the Knowledge Database and, in general, to better prepare the operational support staff.
Review and closure
The main purpose of deployment closure is to formally close the release, and to verify that the Configuration Management System (CMS) is up to date with the newly released service.
This is also a good opportunity to capture the customer / end user experience through feedback, and underline any quality criteria that may not be met. Just make sure that there are no resource, capability, capacity or performance issues left at the end of the deployment, and that the customer accepts any problems, known errors, or workarounds that may have been in place after deployment.
Once the service is ready to make the transition from early life support into operation, the official handover for service support will be performed between the deployment group and service operations. In general, Change Management performs the post-implementation review.
Those who do not learn from history are doomed to repeat it.
I’ve seen IT departments that look more like research and development labs. In such environments, things tend to escalate after key IT personnel are changed, or when major change is required (if it’s even possible to attempt it, because of the risk that even the slightest change may break the whole service). Therefore, having a strong IT organization that revolves around the Incident Management – Change Management – Release and Deployment Management triangle will allow you to handle day-to-day challenges with less stress to whole Service Management team.
I may have mentioned it before, but if you’d ask me what differentiates good IT Service management from bad, the answer would be in the way they handle changes. Everything in IT Service Management is change, and release is where change becomes visible.
To implement ISO 20000 easily and efficiently, use our ISO 20000 Documentation Toolkit that provides step-by-step guidance for full ISO 20000 compliance.



